
「いづれの御時にか、女御更衣あまたさぶらひける中にいとやむごとなき際にはあらぬが、すぐれてときめきたまふありけり」で始まる『源氏物語』。平安時代中期(11世紀)に成立した宮廷の恋愛物語は、世界最古の長編小説として有名だが、江戸時代の人々にすら極めて難解なことばの集合で、多くの注釈書が発刊されていた。
ことばは時代と共に変化し、それを正しく理解することは失われた意味を復元する作業にも似る。冒頭にかかげた源氏の一節も、教えてくれる人がいなければ、それぞれの単語がどこで切れるのかすら判然としない。
言語を確率論的にとらえ、計算式によって解析(処理)するなら現代語も古典も、未知の言語すらも容易に理解できるようになる――このように考えて「計算言語学」の旗をかかげる統計科学者がいる。

- 持橋 大地
- 数理・推論研究系
学習推論グループ准教授
言語の差異構造を統計的に理解する
持橋の専門分野は、「統計的自然言語処理」と「統計的機械学習」。それは簡単に表現するなら、言語を数学と統計の力を使ってモデル化しようとする科学である。「言語には様々な意味で人により、地域により、時代によってバリエーションがあり、同時にそれらには共通性がある。そうした言語の差異の構造を統計的手法によって理解したい」と持橋は言う。
「計算言語学は言語のもつ統計的な性質に着目し、機械翻訳、構文や意味の解析、感情情報の処理といった様々な応用を可能にする分野です」。持橋は言語の文字列に適切な確率を与えて統計モデル化する研究に取り組んできた。まず、単語の出現が話題や文脈によって異なること、意味的に関係のある単語群が同時に現れる傾向があることに注目し、話題の「文脈」を時系列としてモデル化することを試みた。大量の新聞記事から細かい話題を統計的に抽出する統計モデルを利用し、「話題の変化」を自動的に見つける研究に打ち込んだという。ここから、持橋は「単語に次の単語が続く確率、また、文字に次の文字が続く確率をすべてモデル化することができれば、言語の形態を鮮明に印象づけることができるのではないだろうか」と考えた。

「教師なし形態素解析」で文章を読み解く
たとえば、宮沢賢治(1896-1933年)の代表作『銀河鉄道の夜』を例に考えてみよう。賢治の没後に発表されたこの作品は、「けれどもほんたうのさいはひは一體何だらう」など、主人公の華麗な台詞と造語にあふれている。
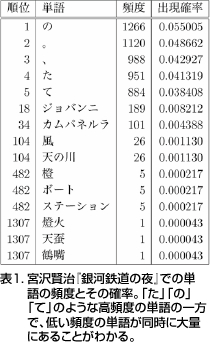
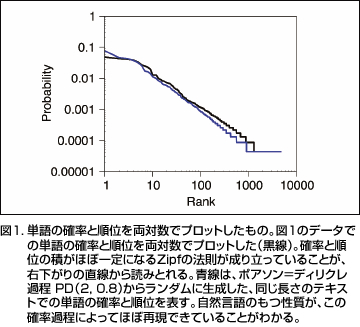
この作品を構成する単語に分解し、統計的な観点から考察すると、ひんぱんに現れる単語と、そうではない単語があることが容易に見てとれる(表1)。単語のそのような出現頻度の実態は、「ポアソン=ディリクレ過程」という統計モデルで説明できる。持橋によれば、「それは簡単に言うと“rich gets richer”つまり、いったん頻度が高くなった単語はどんどん頻度が高くなるという現象のモデル化で説明される」という。具体的には「た」「の」「て」のような高頻度の単語がある一方、低い頻度の単語が同時に大量にあることを指摘できる。『銀河鉄道の夜』では「橙」「ステーション」「天蚕」などの単語が該当する。そして、確率と順位の積がほぼ一定になるZipfの法則が成り立っていることが右下がりの直線から読みとれる(図1)。
このような方法から生み出された統計モデルを使えば、未知の言語や古文、話し言葉などの単語分割が可能になるというのが、統計学者としての持橋の考え方だ。持橋はそれを「教師なし形態素解析」の手法と呼んでいる。
『源氏物語』に話を戻す。難解な読みも上記の統計モデルを用いて解析すると、図2のように、意味を持つ単語の区分が明らかになり、容易に読み進めることができるようになる。これは持橋が学会で発表した具体例であり、多くの研究者に驚きを与えた。
持橋は、自然言語処理と数学の接点をテーマにしたエッセーで、次のように書いている。「言語を統計的にとらえることによって、複雑で膨大な言語現象を計算機で自動的にモデル化できるとともに、規則ではとらえきれない曖昧性や例外、文脈依存性を数学的に適切に扱うことが可能になる」。
ことばの不思議な「構造」を探り続ける
「自分では統計学者というよりは、言語学者のつもり」。そのように自認する持橋の研究姿勢は、統計学を道具にして言語の世界の不思議に迫ろうとする営みである。
その一方で、「言語を言語学者の主観から解き放ちたい」とも、持橋は語る。「源氏物語を例にした単語分割の研究は確かに私の代表的な研究成果ですが、基本は言語構造を統計的にとらえたいということ」。学者の経験と主観によって生み出された仮説を積み重ねる従来の言語学は、「生きたことば」の構造解明には対応できなくなっている、というのが持橋の主張だ。
ところで、持橋は少年時代から大の音楽好きだった。高校では合唱部の指揮者。「自分のパートをきわめるだけではなく、曲の全体像を理解したいと、いつも思っていた。一方で楽譜も一種の記号であると考えていた。今から振り返ると、音が作り出す数理に惹かれていたのだと思う」。音楽の中に、数学的な言語の構造を見出そうとする姿勢が、当時から育まれていたようだ。
文系で入学した大学の3年次に理転してコンピュータサイエンスを専攻。奈良県の大学院卒業後、NTTの研究所を経て2011年に統数研入り。統計的機械学習のバイブルともいえる教科書『パターン認識と機械学習』の訳者の一人でもある。
「言葉の配列の中に隠れているもの、つまりリズムや反復などの確率を、統計的手法を使って表に出すのが私の仕事。普通の生活の中で日々接している言葉を、どうやって機械に乗せることができるだろうか、といつも考えている」と語る。
時代とともに海のように広がっていく言語現象。広大さに対峙するかのように、統計研究の立場からの問いかけが続く。
(広報室)

![]()