
n個体についてp次元のデータ(n×p個)が得られたとします。これを行列の形で表現したものがデータ行列です。
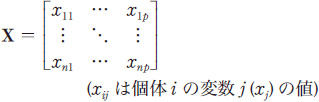
得られたデータが何らかの計測値であるとし、それぞれの変数の平均値をと書くことにします。上記のデータ行列の要素xijをx*ij=xij−で置換えて得られるデータを、中心化したデータといいます。中心化したデータx*ijを要素にする行列をX*、その転置行列をXt*と書くことにすると、V=Xt*X*/nは対角要素に変数の分散、非対角要素に変数間の共分散を配置した分散共分散行列になります。

- 馬場 康維
- データ科学研究系
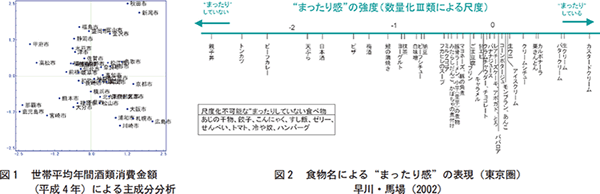
49都市の布置
分散共分散行列を用いた多変量解析の手法の一つである主成分分析を用いた面白い(だまされやすい)例を示しましょう。
総務省統計局の家計調査によって様々な品目の日々の消費金額や量が調査されています。その中の酒類の世帯あたり年間消費金額をもとに49都市を2次元平面にプロットしてみます。49都市とは、東京23区を一つとみなして、都道府県庁所在地に川崎市、北九州市を加えたものです。用いた変数は49都市の世帯平均の年間酒類消費金額で、平成4年のデータです。清酒、焼酎、ビール、国産ウイスキー、輸入ウイスキー、ぶどう酒の消費金額が変数になります。主成分分析を適用して第1、第2の二つの主成分で都市をプロットした図を見ると、九州では焼酎、東北北陸では清酒というイメージによくあう結果が得られます。ところが、焼酎という変数をはずしてもこの図はほとんど変化しません。この図を描くために用いた第1主成分と第2主成分には焼酎はほとんど寄与していないからです。このような変数の寄与の問題は、変数に重みをつけて分析を行う“強制分類”という方法を用いると解釈が容易になります。
ことばの計量
“まったり”ということばは出身地、世代によって感じ方が異なります。共同研究者が調査を行い食品のまったり感の数量化を試みました。調査データは質問への回答から成り立ちます。食品のまったり感を変数とすると、変数の値は(まったりしている、まったりしていない)で、回答を(1, 0)または(0, 1)で表すことになり、データ行列は1と0からなるものになります。分散共分散行列に当たるものはXtXで、これはクロス集計表です。つまり、数量化はクロス集計表をもとに行われます。実際に食品をまったりしている順にならべたものが図2です。
多次元データ解析研究
“多くの観測は多次元的であり、量を測るものと質を評価するものと様々な観測の組合せになります。時には、データを観測しそこなって欠測値ができることもあります。こういうとき、欠測値が(ある、ない)を(1, 0)に対応させて、変数とみなすことも可能です。また、時点の異なる多次元のデータの連結解析なども必要になります。まだまだ研究テーマは尽きません。
参考文献
1. 早川文代, 馬場康維(2002). 流行語としての“まったり”の客観化−首都圏におけるアンケート調査−, 日本家政学会誌、53巻5号, 437-446.
2. 早川文代, 馬場康維(2002). 方言としての“まったり”の客観化−京都地方のアンケート調査および聞き取り調査−,日本家政学会誌, 53巻5号, 447-456.
3. Nishisato, S. and Baba, Y. (1999). On contengency, projection and forced classification of dual scaling. Behaviormetrika, Vol.26, No.2, 207-219.
![]()